
17 AI Maturity Frameworks Exist. None of Them Work. Here's Why.
I analyzed 17 AI maturity frameworks from Gartner, McKinsey, Accenture, Microsoft, and others. They don't agree on how many levels exist, what to measure, and score it. None of them covers AI agents.
Last week I made the case that organizational maturity - not data quality - is the real reason AI projects fail. The research is clear: 95% of AI pilots produce zero P&L impact, and the root cause is “flawed enterprise integration,” not bad models or messy databases.
The natural next question is: how mature are we, exactly? If maturity is the problem, you need a way to measure it.
So you go looking for a framework. And you find seventeen of them.
That’s not a market. That’s a red flag.
17 frameworks, 17 definitions of “mature”
I spent the past month pulling apart every major AI maturity framework I could find: Gartner, McKinsey, Accenture, Microsoft, Google Cloud, AWS, Deloitte, PwC, IBM, MIT CISR, Salesforce, MuleSoft, OneReach, Bain, NIST, ISO 42001, and OWASP.
The first thing you notice is that they can’t agree on the most basic structural question: how many steps does the staircase have?
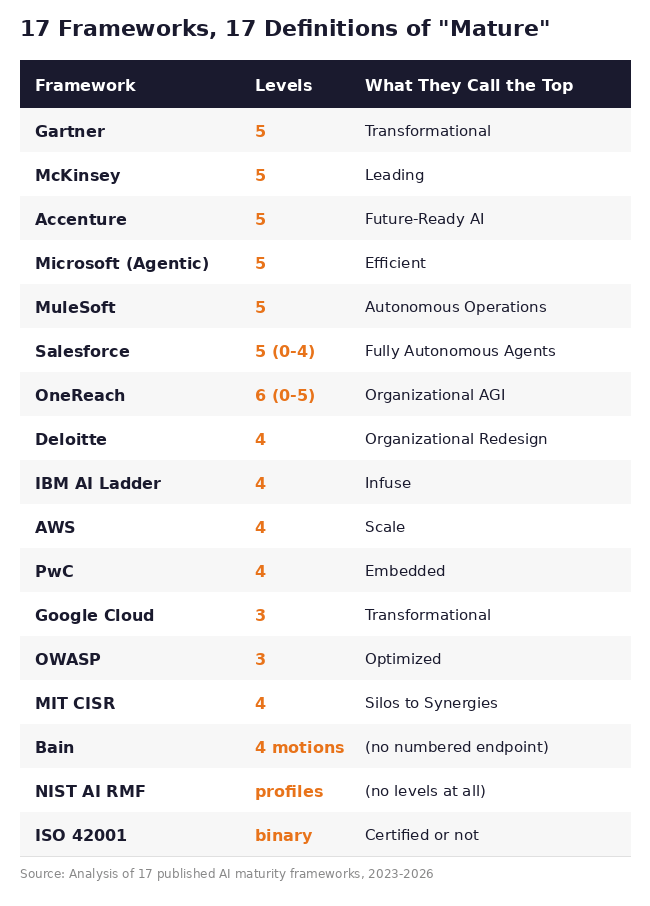
Three levels, four levels, five levels, six levels. Or no levels. Or binary pass/fail. OneReach’s top level is called “Organizational AGI” - a concept that doesn’t exist yet. Gartner and Google both call their top level “Transformational” but mean completely different things by it. NIST doesn’t believe in levels at all; it uses current-state vs. target-state profiles with gap analysis. And ISO 42001 reduces the entire question to a compliance audit: you’re either certified or you’re not.
If the industry can’t agree on how many steps the staircase has, you’re not climbing the same staircase.
Same company, different score
The structural disagreement goes deeper than level counts. These frameworks measure fundamentally different things.
Accenture evaluates 8 dimensions and produces a score from 0 to 100 - where the median organization lands at 36 and “AI Achievers” average 64. MIT CISR calculates a “Total AI Effectiveness” percentage. Google assigns you a phase (Tactical, Strategic, or Transformational). PwC classifies you into a stage based on responsible AI practices. ISO says you have 38 controls and you either pass the audit or you don’t.
Here’s the measurement landscape across all 17:
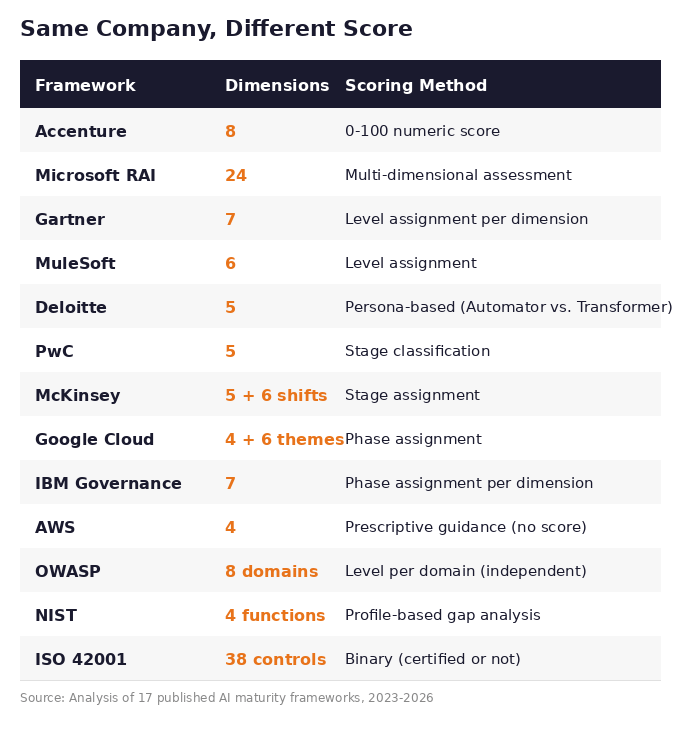
Run the same organization through Accenture’s model and you might get a score of 42 - “Implemented AI.” Run it through PwC’s model and you’re “Strategic stage” because you have strong responsible AI practices. Put it through ISO 42001 and you fail certification because three of the 38 controls aren’t documented. Apply the NIST framework and there’s no score at all - just a list of gaps between where you are and where you want to be.
Four frameworks, four verdicts, zero overlap.
This matters because these assessments drive real decisions. They determine where budget goes, which projects get approved, and how leadership reports AI progress to the board. When the tool you use to measure maturity changes the measurement itself, you don’t have assessment. You have astrology with better slide decks.
The vendor problem hiding in plain sight
There’s a structural reason these frameworks disagree, and it’s not academic.
Salesforce’s maturity model measures readiness to adopt Agentforce. Microsoft’s agentic model measures readiness for Copilot and Azure AI Services. Google Cloud’s framework assesses progress toward Vertex AI adoption. IBM’s AI Ladder leads to watsonx. AWS’s model is explicitly about Amazon Bedrock.
These aren’t neutral assessments. They’re sales funnels with maturity language.
The pattern is consistent: score low on dimension X, and the recommended action is to buy product Y - from the same company that built the framework. Accenture’s model, developed with Carnegie Mellon’s SEI, is the most academically grounded of the vendor models. But even their assessment feeds directly into Accenture’s consulting and implementation services.
The independent frameworks - NIST, ISO, OWASP - don’t have this vendor bias. But they have a different problem: they’re designed for compliance and risk management, not for operational maturity assessment. NIST tells you where your risks are. ISO tells you if your management system is auditable. Neither tells you how to get from “we have a chatbot in customer service” to “AI is embedded in how we operate.”
So the vendor models measure operational readiness but point you toward their platform. The independent models avoid vendor bias but don’t measure operational readiness. Nobody covers both.
The agent-shaped hole
All of this might be a solvable problem if the frameworks at least covered the same ground. But there’s one area where the gap is catastrophic: AI agents.
Deloitte’s 2026 survey of 3,235 enterprise leaders found that 73% plan to deploy AI agents within two years. But only 21% have governance frameworks mature enough to handle them. That’s a 52-percentage-point gap between ambition and readiness.
Gartner predicts that 40% of agentic AI projects will be canceled by 2027 - not because the technology fails, but because organizations aren’t prepared.
And the maturity frameworks? Most were built before the agentic shift.
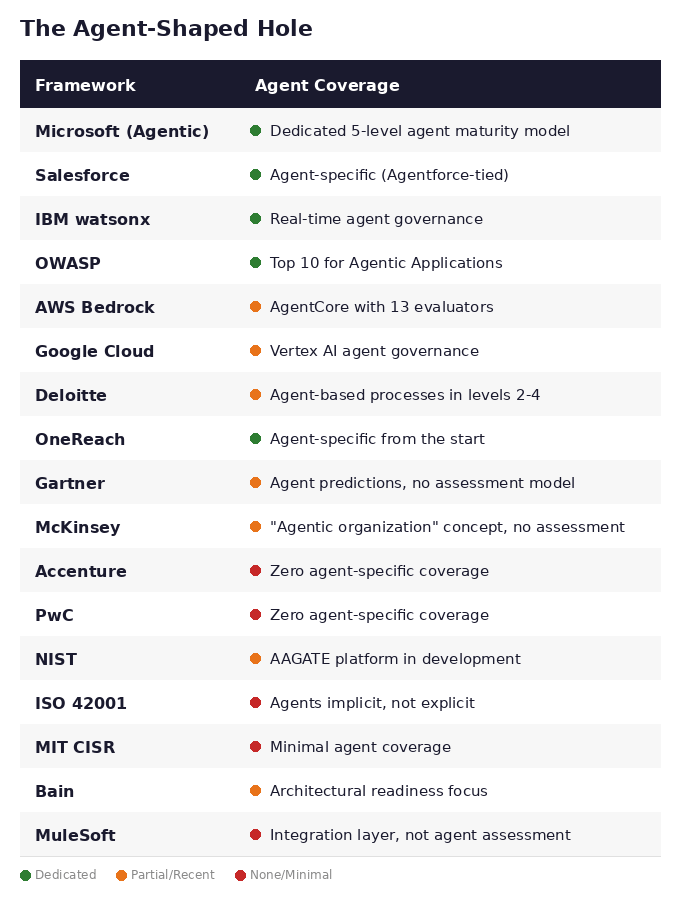
Only Microsoft has a dedicated, structured agent maturity model. Salesforce and OneReach have agent-specific models too, but they’re tied to proprietary platforms. IBM has the most advanced agent governance tooling. OWASP covers agent security. The rest either added agent modules recently, mention agents in passing, or ignore them entirely.
Meanwhile, every enterprise is deploying agents. The frameworks were supposed to tell you if you’re ready. Most of them don’t even know you’re asking the question.
The deeper problem nobody is naming
Even if one framework were perfect - right number of levels, right dimensions, no vendor bias, full agent coverage - it would still miss the most important signal.
Every framework produces a single, organization-wide maturity score. “You are at Level 3.” “Your AI Effectiveness is 62%.” “You are in the Strategic phase.”
That number is as misleading as GDP per capita.
An organization at “Level 2 average” where every team sits between 1.5 and 2.5 is fundamentally different from one at “Level 2 average” where the data science team is at 4, marketing is at 3, and operations and HR are at 0. The second organization has the same average score but radically different operational reality. The data science team is deploying production models. Operations is running everything manually. There’s no cross-functional synergy because half the teams can’t participate.
The standard deviation between teams matters more than the mean.
An organization with low average but tight variance can grow systematically. Train everyone, improve together, build processes that scale across departments. An organization with the same average but high variance has a political problem first and a maturity problem second: the advanced teams resent the laggards, the laggards feel left behind, and every cross-functional AI initiative stalls because the weakest link determines the pace.
No framework measures this. Not one of the 17 I analyzed even mentions intra-organizational variance as a dimension. They all assume the organization is a monolith that can be assigned a single score.
Ask any VP of Engineering whether every team in their org is at the same maturity level and they’ll laugh. Yet that’s exactly what these frameworks assume when they produce a single number.
What this means for you
I’m not going to pretend there’s an easy fix here. If 17 frameworks from the world’s largest consulting firms, tech companies, and standards bodies haven’t converged on a shared definition, adding an eighteenth won’t solve it.
But there are three things worth doing right now.
First, stop treating any single framework as ground truth. If you’re using Gartner’s model because “it’s Gartner,” understand that you’re getting Gartner’s definition of maturity, measured by Gartner’s dimensions, through Gartner’s lens. That’s one perspective, not the answer.
Second, check the agent question. If your organization is planning to deploy AI agents - and statistically, it probably is - ask whether your current assessment framework has anything to say about it. If the answer is “not really,” your assessment is already outdated. The thing you’re about to deploy is the thing your measurement tool doesn’t cover.
Third, look inside before you look outside. Before you pick a framework, ask a simpler question: do the teams in your organization even agree on what “AI mature” means? If the ML team thinks maturity is about model performance, product thinks it’s about feature adoption, and legal thinks it’s about compliance, no external framework will resolve that disagreement. It’ll just paper over it with a score.
The framework problem isn’t going to be solved by a better framework. It’s going to be solved by getting clearer about what you actually need to measure, why, and for whom.
That’s a harder conversation. It’s also a more useful one.
